
بیماری های قلبی عروقی (CVD) یکی از دلایل اصلی مرگ و میر در سراسر جهان است و آنها را تهدید کننده زندگی می کند. برای تشخیص به موقع این بیماری ها برای درمان مناسب، محققان استفاده می کنند فراگیری ماشین الگوریتم ها و تکنیک های تجزیه و تحلیل مجموعه داده های پزشکی بزرگ و پیچیده قلب، دومین عضو اصلی، خون را پمپ می کند و آن را به همه اندام ها می رساند. پیش بینی وقوع بیماری قلبی در حوزه پزشکی بسیار مهم است و تجزیه و تحلیل داده ها به مراکز پزشکی کمک می کند تا بیماری های مختلف را پیش بینی کنند. تکنیکهایی مانند شبکههای عصبی مصنوعی (ANN) و اختلالات قلبی با استفاده از جنگلهای تصادفی و ماشینهای بردار پشتیبانی پیشبینی میشوند. محققان در حال کار بر روی نرم افزاری هستند که از الگوریتم های یادگیری ماشینی برای کمک به پزشکان در پیش بینی و تشخیص بیماری قلبی استفاده می کند.
معرفی
بیماری قلبی یک مشکل عمده بهداشت جهانی است که سالانه باعث 17.7 میلیون مرگ و 31 درصد از کل مرگ و میرها در سراسر جهان می شود. آنها به علت اصلی مرگ و میر در هند تبدیل شده اند و 1.7 میلیون نفر در سال 2016 جان خود را از دست دادند. این بیماری ها در حال افزایش هستند. مراقبت های بهداشتی هزینه ها و کاهش بهره وری، با برآوردها حاکی از آن است که هند به دلیل بیماری قلبی تا 237 میلیارد دلار ضرر کرده است. تکنیک های هوش مصنوعی و یادگیری ماشینی می توانند به پیش بینی دقیق وجود یا عدم وجود بیماری قلبی کمک کنند. استفاده روزافزون از فناوری اطلاعات در مراقبت های بهداشتی به پزشکان در تصمیم گیری، مدیریت بیماری ها و کشف الگوها در میان داده های تشخیصی کمک می کند. جاری بررسی ادبیات و رویکردهای مرور سیستماتیک برای پیشبینی خطر قلبی عروقی اغلب در شناسایی افرادی که از درمان پیشگیرانه یا مداخله غیرضروری سود میبرند، ناکام میمانند.
بررسی ادبیات
نویسندگان دریافتند که ماشین بردار پشتیبان (SVM) به حداکثر دقت 79.12٪ با 37 تقسیم عدد و 6 گره برگ دست یافت، در حالی که درخت تصمیم با 5 برابر به 79.54٪ رسید. الگوریتم جنگل تصادفی که از درخت های تصمیم برای رای گیری و طبقه بندی استفاده می کند، با 20 تقسیم، 75 درخت و 10 برابر به دقت 85.81 درصد دست یافت.
یک مجموعه داده
مجموعه داده Heart که در یک مخزن یادگیری ماشینی موجود است، شامل 303 نمونه و 14 ویژگی ورودی است که جنبه های مالی، شخصی و اجتماعی متقاضیان وام را توصیف می کند. شامل 700 مورد اعتبار خوب و 300 مورد اعتبار بد است.
جنگل تصادفی
جنگل تصادفی یک روش یادگیری ماشینی نظارت شده است که با در نظر گرفتن چندین درخت تصمیم قبل از تولید نتیجه، وظایف طبقه بندی را بهتر انجام می دهد. در طبقه بندی از روش رای گیری و در رگرسیون از میانگین تمامی نتایج درخت تصمیم استفاده می کند.
ماشین های بردار پشتیبانی می کند
ماشینهای بردار پشتیبان (SVM) طبقهبندیکنندههای خطی و غیرخطی هستند که در آموزش و آزمایش مجموعههای داده استفاده میشوند. آنها به دلیل عملکرد تجربی خوب و توانایی در اشتباه کردن محبوب هستند. طبقه بندی کننده های SVM در بسیاری از کاربردها استفاده می شوند و در تحقیقات اخیر نسبت به Bayes ساده ترجیح داده می شوند.
شبکه های عصبی مصنوعی
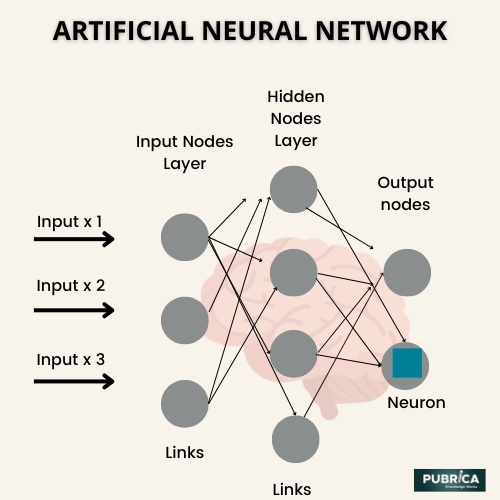
شبکه های عصبی (ANN) برای شبیه سازی سیستم های عصبی، همگام سازی ماژول های لایه استفاده می شود. آنها با آرایش چندین نورون در لایه ها، با لایه های ورودی و خروجی ساخته می شوند. هر نورون یک تابع فعال سازی دارد و پارامترهای شبکه وزن و بایاس هستند. هدف این است که پارامترهای شبکه را یاد بگیریم تا نتیجه پیشبینیشده با استفاده از انتشار پسانداز در تابع ضرر با حقیقت زمین مطابقت داشته باشد.
مقایسه با مدل های ارزیابی ریسک سنتی:
عملکرد مدلهای یادگیری ماشین را در مقایسه با تکنیکهای کلاسیک ارزیابی ریسک مانند امتیاز ریسک فرامینگهام یا SCORE ارزیابی کنید. مزایای بالقوه را برجسته کنید فراگیری ماشینمانند افزایش دقت و پیش بینی ریسک شخصی.
برای کسب اطلاعات بیشتر در مورد خدمات پروپوزال تحقیق، به آموزش ما در مورد راهنمای گام به گام برای توسعه یک پیشنهاد تحقیقاتی مؤثر مراجعه کنید.
بحث
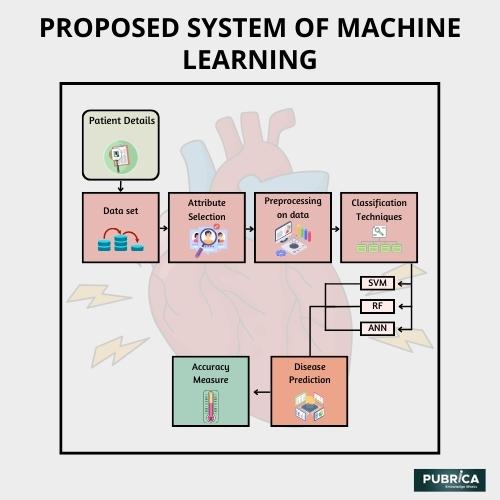
ماشین بردار پشتیبان، شبکه عصبی مصنوعی و تکنیکهای طبقهبندی دادههای جنگل تصادفی استفاده شد. این پروژه شامل تجزیه و تحلیل مجموعه داده های بیماران قلبی و پردازش صحیح داده ها بود. سپس مدل های زیر با بالاترین امتیاز ممکن آموزش و آزمایش شدند:
- طبقه بندی بردار پشتیبانی: 84.0 %
- شبکه عصبی: 83.5%
- طبقه بندی جنگل دلخواه: 80.0%
نتیجه
در نتیجه این بررسی سیستماتیک نقش رو به رشد یادگیری ماشینی در ارزیابی خطر بیماری های قلبی عروقی را برجسته می کند. الگوریتمهای یادگیری ماشینی نویدبخش افزایش دقت پیشبینی خطر هستند و رویکردی پویا و شخصیشده برای سلامت قلب و عروق ارائه میدهند. اگرچه الگوریتمها و مجموعههای داده متفاوتی مورد بررسی قرار گرفتهاند، نیاز به منابع داده استاندارد و معیارهای ارزیابی برای تسهیل مقایسه مستقیم وجود دارد. علاوه بر این، ادغام این مدلهای پیشرفته در عمل بالینی پتانسیل بسیار زیادی برای مداخله زودهنگام و بهبود نتایج بیمار دارد. همانطور که به جلو می رویم، پرداختن به محدودیت های داده ها و اطمینان از تفسیرپذیری مدل چالش های مهمی هستند. با این حال، چشم انداز در حال تکامل یادگیری ماشین در قلبی عروقی مراقبت راه های جدیدی را برای پیشگیری و مدیریت بیماری قلبی باز می کند.
ما را بررسی کنید مثال ها برای درک سازگاری ما در موضوعات و زمینه های موضوعی.
درباره Pubrica
تیم پژوهشگران و نویسندگان Pubrica به توسعه علمی و پزشکی می پردازند خدمات تحقیقاتی که می تواند به عنوان ابزاری ضروری برای پزشک/نویسندگان عمل کند. بررسی سیستماتیک ما از پوبریکا در هر مرحله از نگارش ساختار بیشتری دارد و ما با استفاده از چک لیستهای روششناختی استاندارد مانند PRISMA، CASP، AMSTAR و ARIF و غیره، بر اساس چک لیست ارائه شده، از بررسی سختگیری بحرانی اطمینان میدهیم. کارشناسان ما از ساختاری که موضوع کلی، مسئله و پیشینه را دنبال می کند آگاه هستند و برای بیان فرضیه به یک موضوع محدود می روند.
منابع
- عزمی، جاوید و همکاران “بررسی سیستماتیک رویکردهای یادگیری ماشینی برای پیش بینی بیماری های قلبی عروقی با استفاده از داده های پزشکی بزرگ.” مهندسی پزشکی و فیزیک 105 (2022): 103825.
- رینده، بابان یو و دیگران. “پیش بینی بیماری قلبی با استفاده از یادگیری ماشین.” بیماری قلبی 5.1 (2021).
- اسلامسایفول، نصرت جهان و مست اشیتا خاتون. “پیش بینی بیماری های قلبی عروقی با استفاده از پارادایم های یادگیری ماشین.” 2020 چهارمین کنفرانس بین المللی روش های محاسباتی و ارتباطات (ICCMC). IEEE، 2020


